
As the rapid evolution of artificial intelligence unfolds, developers are faced with critical choices when it comes to enhancing the performance of large language models (LLMs) tailored for specific applications. Two prominent methods—fine-tuning and in-context learning (ICL)—have emerged at the forefront of this discussion. A recent comprehensive study by researchers at Google DeepMind and Stanford University has profoundly explored these approaches, revealing significant insights into their strengths and weaknesses. The study not only emphasizes the potential of ICL in terms of generalization but also introduces a groundbreaking concept: augmented fine-tuning.
The Dynamics of Fine-Tuning and In-Context Learning
Fine-tuning refers to the iterative process of taking a pre-trained LLM and adjusting it to perform better on task-specific datasets. This adjustment occurs by recalibrating the model’s internal parameters, effectively reprogramming it based on new, often specialized data. In contrast, ICL takes a different approach by using examples embedded directly within the input prompts without altering the model’s underlying parameters. It allows the LLM to adaptively learn how to respond to similar queries based on the provided context.
While fine-tuning can yield positive results for specialized tasks, it often falls short when handling unfamiliar or varied situations. The study’s results reveal that while fine-tuning is beneficial, it may struggle with the generalization capabilities anticipated by developers, especially in scenarios with unique data structures or requirements.
Exploring Generalization: A Rigorous Comparison
The researchers embarked on a critical investigation to compare the generalization capacities of these methods. To do this, they created intricate synthetic datasets featuring complex, self-consistent structures, ensuring that their tests accurately reflected the models’ abilities to learn and adapt. By replacing all fundamental components with arbitrary terms, they crafted a testing environment devoid of pre-trained biases, ultimately allowing for a more rigorous examination of the models’ capabilities.
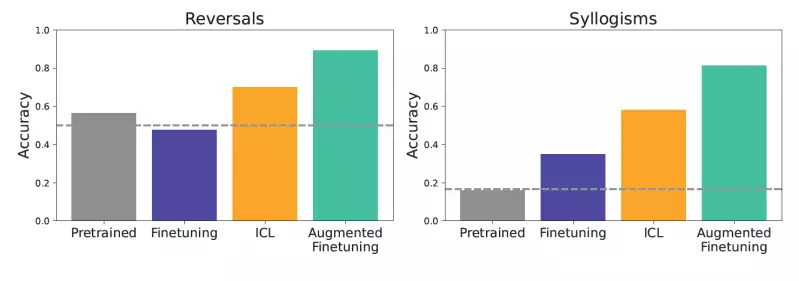
Among the intriguing tests conducted were simple logical inferences and reversals. For instance, if a model learned that “femp are more dangerous than glon,” it needed to deduce that “glon are less dangerous than femp” effectively. This approach not only tested basic comprehension skills but also invited models to extend their reasoning beyond straightforward prompts, emphasizing the nuances of understanding complex information.
The Advantage of In-Context Learning
The findings underscored a crucial point: ICL demonstrated a more pronounced ability to generalize across diverse tasks compared to traditional fine-tuning. Models utilizing ICL aligned more closely with the task demands, revealing a stronger performance in engaging with logical deductions and relationship reversals. For developers, this raises an important consideration: while ICL offers superior immediate performance, its computational costs during inference are considerably higher.
The trade-offs inherent in utilizing ICL versus fine-tuning become a fundamental aspect of decision-making. Though ICL saves training costs by avoiding the need for model adjustments, the expense associated with each use becomes a critical factor to consider, particularly in enterprise environments where efficiency is paramount.
Introducing Augmented Fine-Tuning: A New Paradigm
Recognizing the potential benefits of blending the two approaches, the researchers proposed a novel method known as augmented fine-tuning. This innovative technique combines the benefits of ICL with traditional fine-tuning methodologies, enhancing the training dataset used for fine-tuning with ICL-generated examples. The goal? To leverage the model’s capacity for ICL in the creation of more dynamic and varied training datasets, ultimately leading to stronger models that can better generalize across tasks.
The study outlined two augmentation strategies worth noting. The first is a local strategy where individual sentences or snippets from training data are rephrased or expanded upon, encouraging the model to draw inferences and reversals directly from them. The second is a more global approach, involving full dataset context, allowing the model to generate extended reasoning patterns based on comprehensive knowledge connections.
The Power of Augmented Fine-Tuning in Practice
Results from employing augmented fine-tuning were striking, showcasing substantial enhancements in the model’s performance. The integration of the enriched datasets not only outperformed traditional fine-tuning methods but also positioned itself as a more effective alternative to straightforward ICL applications. For businesses, the implications are potent: by investing time and resources into developing these sophisticated datasets, they can create models that not only function better but also adapt to unexpected real-world challenges with heightened reliability.
As we contemplate this paradigm shift, it’s essential for developers to weigh the computational costs of the augmented fine-tuning process against its performance benefits. The understanding of how augmented techniques translate to improved versatility and accuracy is paramount for shaping future advancements in LLM applications.
Ultimately, the exploration conducted by Google DeepMind and Stanford University paves the way for a deeper comprehension of the complexities inherent in LLM customization, signaling a transformative step toward optimizing artificial intelligence for diverse and intricate tasks across various sectors. As the AI landscape continues to evolve, the principles outlined in this study offer a framework for future innovations, encouraging further investigation into the practical implementations of these findings.
Leave a Reply