
Large language models (LLMs) have been making significant advancements in recent years, with models like GPT-4 from the ChatGPT platform showcasing astonishing capabilities in understanding prompts and generating responses across multiple languages. This begs the question: are the texts and responses generated by these models so convincing that they could be mistaken for human-generated content?
A recent study conducted by researchers at UC San Diego delved into this inquiry by employing a Turing test, a renowned method developed by Alan Turing to evaluate the level of human-like intelligence displayed by machines. The findings from this test, detailed in a paper available on the arXiv server, revealed that distinguishing between the GPT-4 model and a human participant in a two-person conversation proved to be a challenging task.
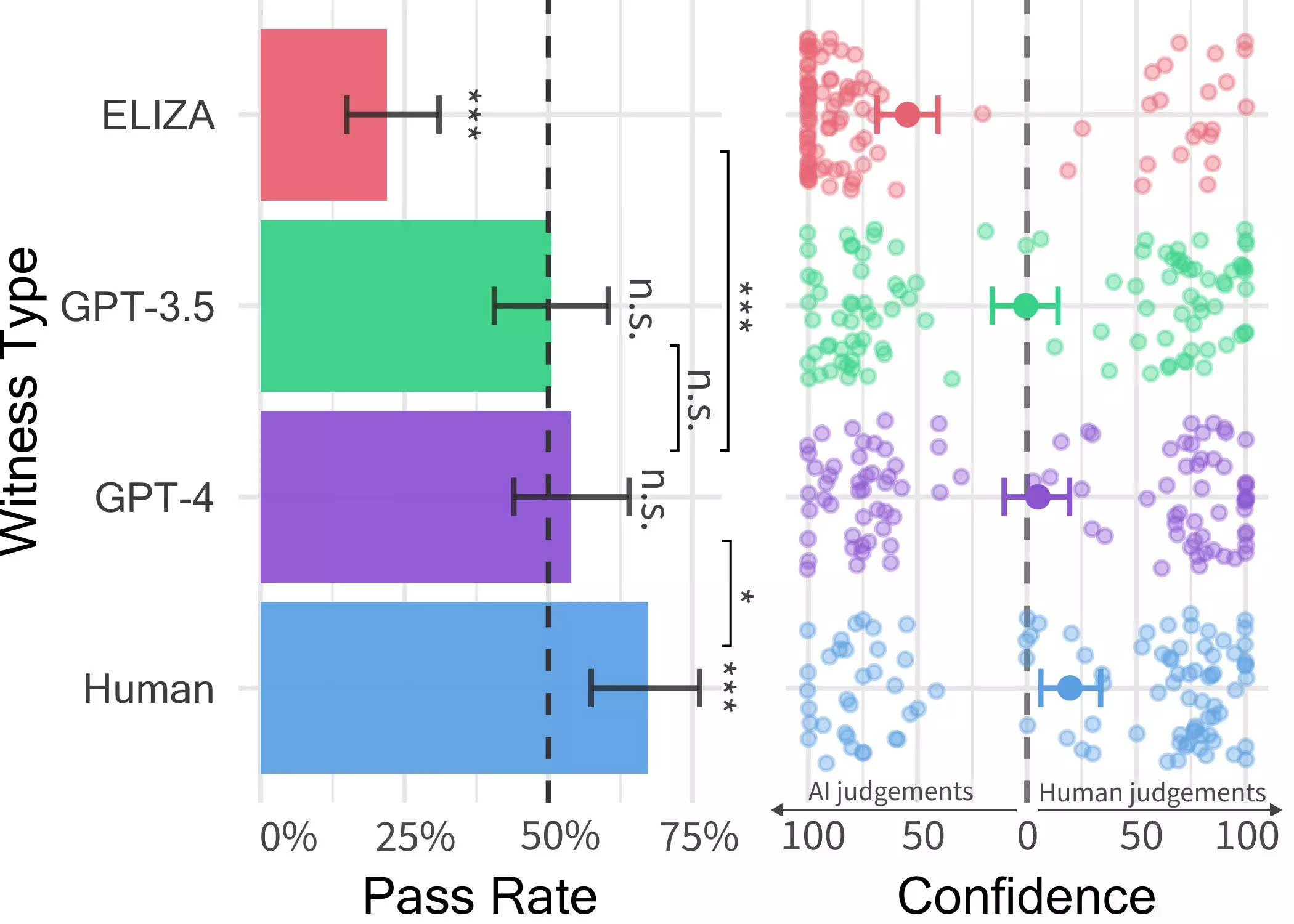
The research initiative was spearheaded by Cameron Jones, who expressed that the inspiration for this undertaking stemmed from a class he was conducting on LLMs. The initial study, overseen by Prof. Bergen from UC San Diego, indicated that GPT-4 could pass off as human in around 50% of interactions. However, recognizing some uncontrolled variables that could impact the outcomes, a subsequent experiment was devised to offer more refined results.
Subsequently, a two-player online game was designed wherein participants engaged in conversations with either a human or an AI agent, attempting to discern the nature of the entity they were interacting with. Throughout the trials, participants conversed freely for up to five minutes, with the interrogator eventually labeling the respondent as either human or machine based on their observations.
Within this experimental setup, three distinct LLMs were evaluated as potential respondents: GPT-4, GPT 3.5, and ELIZA. The outcomes revealed that while users could identify ELIZA and GPT-3.5 as machine respondents, they struggled to differentiate between GPT-4 and human participants, performing no better than random selection.
Jones highlighted that despite human participants being slightly more successful in convincing interrogators of their humanity, the study results suggested that distinguishing between AI systems and humans in real-world scenarios could pose a significant challenge. The implications of this blurred boundary between human and machine interaction could have far-reaching consequences, especially in domains like client-facing services, fraud detection, and combating misinformation.
The study’s findings underscore the remarkable progress made by LLMs, particularly GPT-4, in replicating human-like conversational interactions. This phenomenon hints at a future where online users may increasingly question the authenticity of their interactions, unsure whether they are engaging with humans or sophisticated AI systems.
Looking ahead, the researchers are contemplating an enhanced version of the Turing test, where a third individual would be introduced into the conversation alongside a human and an AI system. This experimental setup aims to shed light on the nuanced differences in communication patterns between humans and LLMs, offering valuable insights into our evolving relationship with artificial intelligence.
Leave a Reply